PBKDF2: performance matters
This is a summary of a talk I gave at Passwords15 on 2015-08-05 in Las Vegas. There are slides and a video:
Overview
The PBKDF2 standards describe the algorithm in such an unhelpful way that almost every defender implementation is at least two times slower than it otherwise could be.
For slow password hashes, performance is important because any inefficiency is passed on to some combination of your user and attacker.
Of the implementations I reviewed, only the following are algorithmically optimal:
- SJCL (forever)
- OpenSSL (post 2013)
- Python core (3.4 and later)
- Django (post 2013)
- BouncyCastle (1.49 and later)
- Apple CoreCrypto (unknown history)
But, in practical terms, all are slower than a public domain implementation I released:
fastpbkdf2
fastpbkdf2 is a public domain PBKDF2-HMAC-{SHA1,SHA256,SHA512} which significantly outperforms others available. For example, it outperforms OpenSSL by about 4x and golang by about 6x.
It does this through a few tricks:
Strategies
-
Aggressive inlining of everything in the inner loop. This makes everything statically available to the compiler so optimisation passes can have full effect. This means the inner loop will get compiled to packed vector SSE2 operations, plus a call to the hash compression function.
-
Compute output in host endianess. This is a minor tweak, but should pay off much more when no endianness conversion is performed (see below).
-
No buffering or padding inside loop. The input to the hash function in the inner loop is always the same length, so MD length padding is done once, outside the loop.
-
Minimal copies and other operations inside loop. OpenSSL does memory allocations/frees and excessive copies.
-
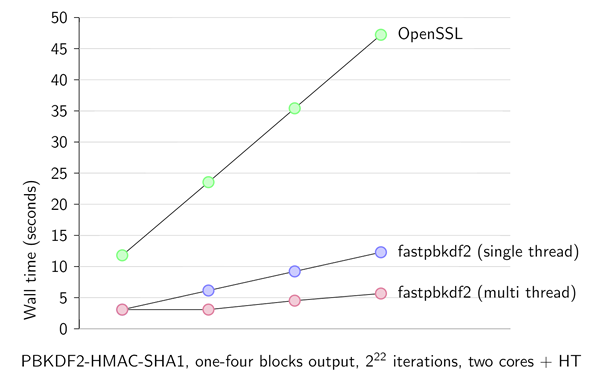
Optional parallelisation of long outputs. PBKDF2's generation of long outputs is exceedingly broken, but in case you need it anyway,
fastpbkdf2can use OpenMP to parallelise this computation.This graph compares making one to four blocks of output using OpenSSL versus fastpbkdf2. Note that when multithreading is enabled, the second block is 'free' (with respect to wall time) and subsequent blocks are slightly faster (thanks to hyperthreading).
Future work
-
Avoid endianness conversions. The input to the compression function is in network order, but needs to be processed in host order. This means order conversions before, during and after the compression function call. However, if we keep everything in host order, we can get rid of these.
I didn't do this yet, because it requires maintaining fast hash function implementations for interesting platforms. At the moment
fastpbkdf2is generally portable.
Reviewed implementations
This review was performed in December 2014. Things might have moved on since then.
- FreeBSD (10): Slow. Measures speed.
- GRUB (2.0): Slow.
- Truecrypt (7.1a): Slow.
- Android (disk encryption): OK. Calls scrypt + openssl pbkdf2.
- Android (BouncyCastle): Slow.
- Django: OK. Fixed by sc00bz CVE-2013-1443.
- OpenSSL: OK. Fixed by Christian Heimes 2013-11-03.
- Python (core >=3.4): OK. Christian Heimes 2013-10-12.
- Python (pypi pbkdf2): Slow.
- Ruby (pbkdf2 gem): Slow.
- Go (go.crypto): Slow (structurally fast, but hmac module lets it down).
- OpenBSD: Slow.
- PolarSSL/mbedTLS: Slow.
- CyaSSL/wolfSSL: Slow (structurally fast, but hmac module lets it down).
- SJCL: OK.
- Java: Slow (structurally fast, but hmac module lets it down).
- Common Lisp (ironclad): Slow.
- Perl (Crypt::PBKDF2): Slow.
- PHP (core): Slow. Pull request submitted upstream.
- C# (core): Slow.
- scrypt (scrypt and libscrypt) Slow but iterations==1, always. yescrypt also.
- BouncyCastle OK (>= 1.49).
- Apple CoreCrypto. OK. Disassembly only (source is not available).